A Filtering Algorithm for Proxy Caches
Michal Kurcewicz, Wojtek Sylwestrzak, Adam Wierzbicki
Interdisciplinary Center for Mathematical and Computational Modeling
University of Warsaw
{mkur, wojsyl, adamw}@icm.edu.pl
Topic: Cache server performance analysis
Introduction
In the past, most work on caching policies and replacement algorithms has been focused on maximizing one performance measure: the hit rate. This was because the hit rate was seen as the best measure of proxy cache service quality. However, maximizing hit rate does not necessarily lead to maximization of proxy cache performance.
A cache spends much time on disk operations, especially - as we shall demonstrate - on disk writes. To maximize hit rate, a cache needs to write as many objects as possible on disk. This leads to a heavy use of disk bandwidth and slows down reading of objects from disk. Another consequence of storing all incoming objects is the increase in main memory storage of metadata. Reducing this storage would free some space for a main memory based hot object cache.
Numerous experiments have shown that WWW cache hit rate seldom exceeds 50%. This fact is due to the large amount of unpopular objects - that is, of objects that appear only once or at most a few times in the request stream over the observation period. In most cases such objects are never accessed after they were placed in the cache. The aim of this work is to demonstrate that caching unpopular documents can be avoided and that doing so may improve overall cache performance. For the above reasons, we call the algorithms presented in this paper filtering algorithms. The goal of such an algorithm is filtering popular objects from the stream of client requests.
Proxy Cache Traces
In our analysis we used the following traces:
The main characteristics of these traces are summarized in table 1.
|
Trace |
Collection period |
# of requests (in thousands) |
# of clients |
Total Traffic (in Gbytes) |
|
ICM |
01 – 14 October 1997 |
2264 |
4596 |
26.3 |
|
PK |
13 – 26 February 1998 |
548 |
1062 |
5.4 |
Table 1:
main characteristics of the analyzed tracesEvery single line in a trace summarizes a transaction - it contains information about the requesting client, attributes of the requested object like its URL or size, and proxy response to that request. Unfortunately access logs generated by standard caching software like Squid [NL] or NetCache [DA97] do not include important consistency information, namely the Last-Modified and Expires dates from server response and If-Modified-Since from the request header. Instead, the trace contains a single field coding proxy actions while serving the request (ex. TCP_ REFRESH_HIT for a situation when a requested object was found in cache, but has already expired so the proxy made a If-Modified-Since request to the origin server to verify that the object is still valid). As it was pointed out in [DU97] the lack of consistency information does not allow for accurate simulation of caches that are larger than the original cache. We would like to add that it also makes impossible the simulation of alternative cache strategies - it is likely that caches using such strategies would store objects not cached by the original proxy, thus no consistency information could be inferred from the trace for these objects.
Since our research involved changing the caching policy, we could not rely on the limited consistency information available in the traces. Therefore we decided to switch to a time-to-live based expiration model - once an object is brought into the cache, it is assigned a time-to-live. On every access the proxy checks whether the requested object has expired - if this is a fact the object is discarded and a request is made to its origin server, otherwise the cached object is returned to the client without further verification of its validity. So we treated If-Modified-Since requests as simple, unconditional requests.
Additionally all objects in a cache are periodically checked and the expired ones are removed. In our simulations we used a time-to-live value of 48 hours (this was the time-to-live setting used by ICM`s proxy on objects for which no expiry date was given by the origin server).
To avoid bias from various client cache configurations we modify our traces on the basis a two simplifying assumption. We assume that clients have infinite caches with time-to-live for objects set to 24 hours. So unless a client forces a reload he does not request the same objects within a 24 hours timeframe. The other assumption is about filling missing data - for some objects that were requested we not observe their true size (ex. the case of 304 Not Modified responses). If the size was missing we assumed that it was equal to the average size of objects in a given category (categories we used were text/html, image, multimedia, archive, java, dynamic content, other). We modified the traces according to these assumptions.
Trace-Driven Simulator
To perform our analysis we developed Cachesim - a trace-driven proxy cache simulator. Trace-driven simulators were often used to evaluate various cache strategies [WI96, DU97,GA97]. Cachesim accepts traces in Squid and Netcache formats. It faithfully simulates the behavior of a proxy on a given input trace. The user is able to control various parameters of the simulated proxy (cache size, object time-to-live time and many more),he can also select among different cache strategies like LRU or SIZE. During a simulation Cachesim generates data about current cache size, hit rate, disk usage and a few more variables.
Cachesim is written in Java, so it offers superior portability - it has been successfully run on various flavors of UNIX and Windows NT.
Empirical Evidence
The distribution of WWW objects popularity has widely studied [BE95, DU97, GA97]. A common finding is that a small number of very popular objects accounts for a large fraction of client requests. In our work we focus on the popularity of Web hosts, since this is a more practical measure.
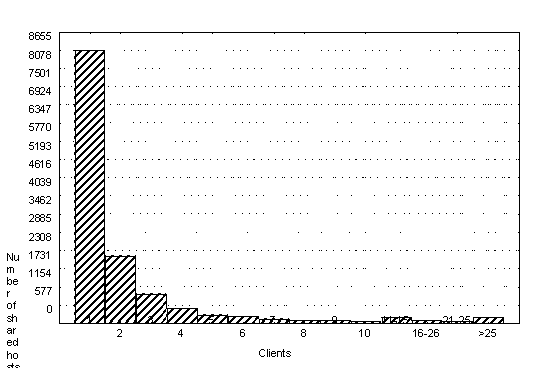
Figure 1 shows how widely hosts are shared among clients in the PK trace. On y-axis we have the number of hosts that are shared by the number of clients shown on the x-axis. Most hosts are not shared (more than 8000 from a total of 13000) and only few host are shared by a large number of clients. Widely shared hosts are more likely to receive a large number of requests than hosts that are shared only by some clients [DU97].
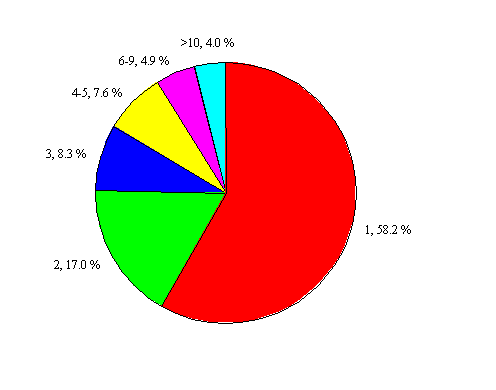
Figure 2 depicts a typical distribution of number of accesses that are made to objects stored in a cache. This pie-chart was obtain from a Cachesim simulation on the PK trace - we recorded the number of requests to objects during their lifetime in the cache. The result is that almost 60% of the object were accessed only one time, these objects once written were never read again. On the other hand, popular objects (which are likely to have 4 or more accesses) are less than 20 %.
.
|
Trace |
Disk Activity |
|
|
Mbytes read |
Mbytes written |
|
|
ICM |
7069 |
16322 |
|
PK |
952 |
4053 |
Table 2:
Simulated disk activity (infinite cache size)In Table 2, the simulated disk activity for an infinite cache from the two traces is shown. In the simulation, all object read request were satisfied from disk and not from main memory. Because of that, in a real cache the amount of read bytes is likely to be smaller. Both traces prove our contention that disk writes form a majority of a cache's disk activity. From our previous analysis of Figures 1 and 2 we see that the reason for this is the large percentage of unpopular objects (residing on non-shared hosts).
The demonstrated empirical and simulation data point to the conclusion that huge savings of disk bandwidth could be obtained by not caching unpopular objects. Also, the filtering out of unpopular objects from the request stream is not likely to decrease hit rate very much, since only a small number of requests are made for these documents.
Filtering Algorithm
To predict object popularity, one can use two approaches. The first is to create an estimate of the probability that an object will be requested in the future on the basis of object characteristics. The most relevant are: the popularity of the origin server, the depth of the object in the server's directory tree, the type of the object and its size. During our research we have created a model of popularity based on these characteristics. However, we evaluated the model using econometric methods [KM86] and found it unsatisfactory for aggregated data. Therefore we leave it for further research.
The second approach is to use client access characteristics. The simplest way to do this is to remember if an object has been requested by some client, and look for accesses from other clients (this is a simple measure to detect object sharing). The parameter of this procedure is the time T for which we remember the object's access. If the object is requested by another client before T seconds pass from the last access, we increment the object's counter. If T seconds pass without such a request, we set the counter to zero.
The described procedure is too expensive to be carried out individually for every object (large memory usage). Therefore, we focus on the origin hosts. The rationale for this is that users tend to request the same objects from one host. So, if hosts are shared, their objects will be shared also. The larger a host's counter, the more requests were made for the host's objects by various users, with intervals between requests smaller than T.
Now let us formulate a caching policy on the basis of the above algorithm for evaluation of popularity. The proposed policy is simple: we will cache an object if the counter of its origin host is greater or equal to one (i.e. we cache an object if regard its origin host to be a shared host). Lower values of T mean that fewer objects will be cached, because fewer hosts will be regarded as shared hosts.
Simulations
To separate the effects of the filtering algorithm and a removal policy, we decided to simulate an infinite cache, hence no removal policy was necessary. First we ran simulations without the filtering algorithm - the results can found in Table 3.
|
ICM |
PK |
|||
|
Number of objects in cache |
861996 |
254641 |
||
|
HTTP accesses |
2264824 |
548360 |
||
|
HTTP hits |
792140 |
127150 |
||
|
Hit rate |
0.34975785 |
0.23187323 |
||
|
Not cacheable |
180299 |
65875 |
||
|
MB sent to clients |
26303 |
5598 |
||
|
MB hit |
7069 |
952 |
||
|
Byte hit rate |
0.268774 |
0.17017756 |
||
|
MB not cacheable |
2912 |
592 |
||
|
MB read from disk |
7069 |
952 |
||
|
MB written to disk |
16321 |
4053 |
||
Table 3
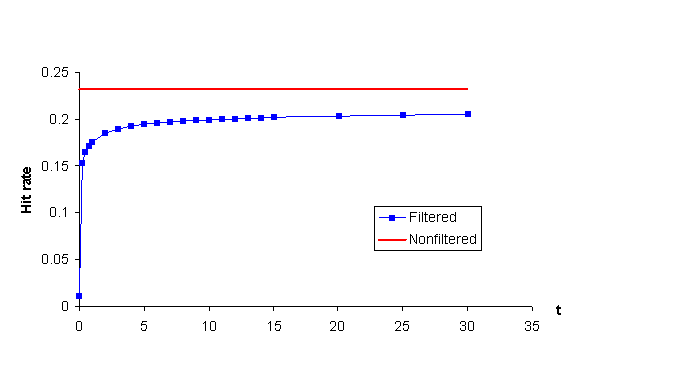
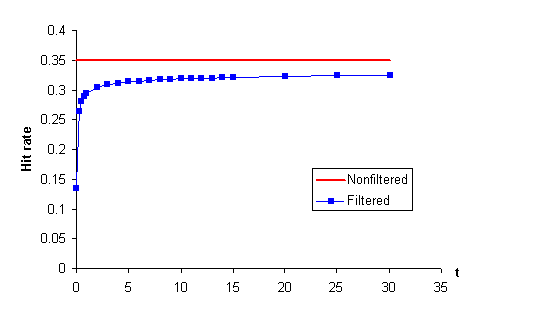
: Results of simulation runs without filteringThen we simulated the cache with filtering turned on. For each of the traces we ran simulations with various values of the parameter T. Figures 3 and 4 show the effects of filtering on hit rate for the PK and ICM traces respectively. Please note that the values of the parameter T in the figures are in minutes, not seconds. For values of T greater than 10 minutes, hit rate is stable and is about 3 % below the hit rate without filtering (for both traces). However if we decrease T below 5 minutes hit rate starts to fall very quickly (this is because the set of shared hosts is getting too small to support a high hit rate). Filtering does not seem to have a strong negative impact on hit rate - unless we set T to very a low value the downward change in hit rate is not large.
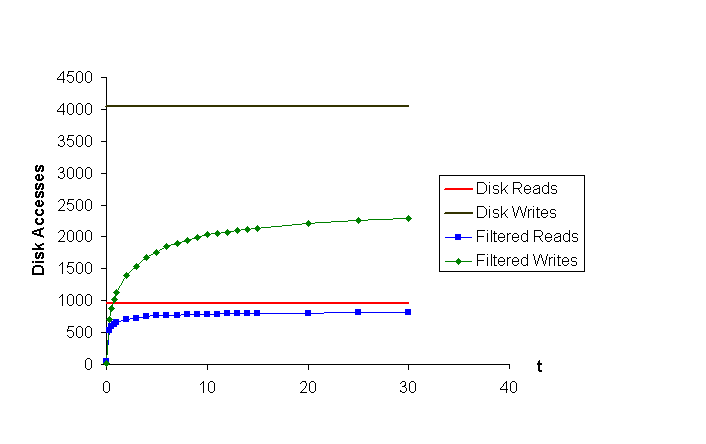
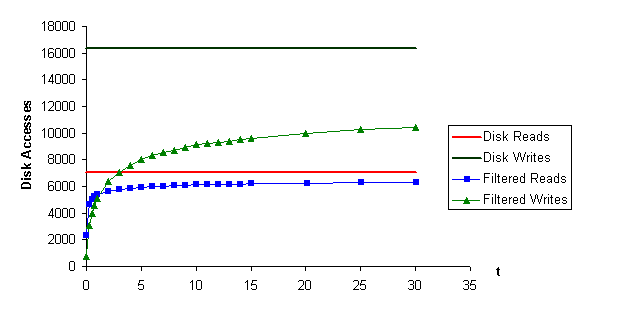
We already know what are the costs of using a filtering algorithm in terms of decreased hit rate. Now we will take a closer look at the benefits filtering can provide. On figures 5 and 6 we can seen the effect of filtering on disk activity. Here the effect introduced by the algorithm is much stronger.
We already know what are the costs of using a filtering algorithm in terms of decreased hit rate. Now we will take a closer look at the benefits from filtering. On figures 5 and 6 we see the effect of filtering on disk activity. Here the effect introduced by the algorithm is much stronger - for a value of T of 10, disk writes in both traces are reduced by 45 %; this reduction is even stronger for lower values of T.
While using filtering algorithms we face a tradeoff - we lower disk and memory load at the price of a lower hit rate. It is not true that the use of filtering algorithms will be beneficial to all - in many cases the costs of higher network usage can outweigh the benefits from a faster service.
Conclusions
In this paper we argued that an aggressive policy that aims to maximizing hit rate by storing every object that is cacheable may not deliver the best performance, because it generates a very high load on disks. As an alternative we propose the use of a filtering algorithm which filters out from the request stream objects that are likely to be accessed in the future. Only these objects are stored in the cache, all others are simply forwarded to clients without making a local copy. We show that our approach gives a significant decrease in disk activity while maintaining high hit rates.
Acknowledgments
We would like to thank Marcin Klimowski at the Technical University of Cracow for providing us access to the PK proxy trace.
References
|
BE95 |
A.Bestavros, C.R. Cunha, M.Crovella, "Characteristics of www client-based traces", Technical report, Boston University, Jul 1995 |
|
DA97 |
P. Danzig, "NetCache Architecture and Deployment", Network Appliance, Dec 1997 |
|
DU97 |
B. M. Duska, D. Marwood, M. J. Feeley, "The Measured Access Characteristics of World-Wide-Web Client Proxy Caches", Proc. USENIX Symposium on Internet Technologies and Systems, Dec 1997. |
|
GA97 |
S. Gadde, M. Rabinovich, J. Chase, "Reduce, Reuse, Recycle: An Approach to Building Large Internet Caches", Proc. of the 6th Workshop on Hot Topics in Operating Systems, May 1997. |
|
KM86 |
J. Kmenta, "Elements of Econometrics", Macmillan Publishing Company, New York, 1986. |
|
NL |
Squid Internet Object Cache, National Laboratory for Advanced Network Research, URL: http://squid.nlanr.net/ |
|
WI96 |
S. Williams, M. Abrams, C. R. Standridge, G. Abdulla, E. A. Fox, "Removal policies in network caches for World Wide Web documents", ACM SIGCOMM ‘96: Applications, Technologies, Architectures and Protocols for Computer Communications, Aug 1996. |